Factual, Controllable, and Interactive Dialogue Agents
ABOUT THIS PROJECT
At a glance
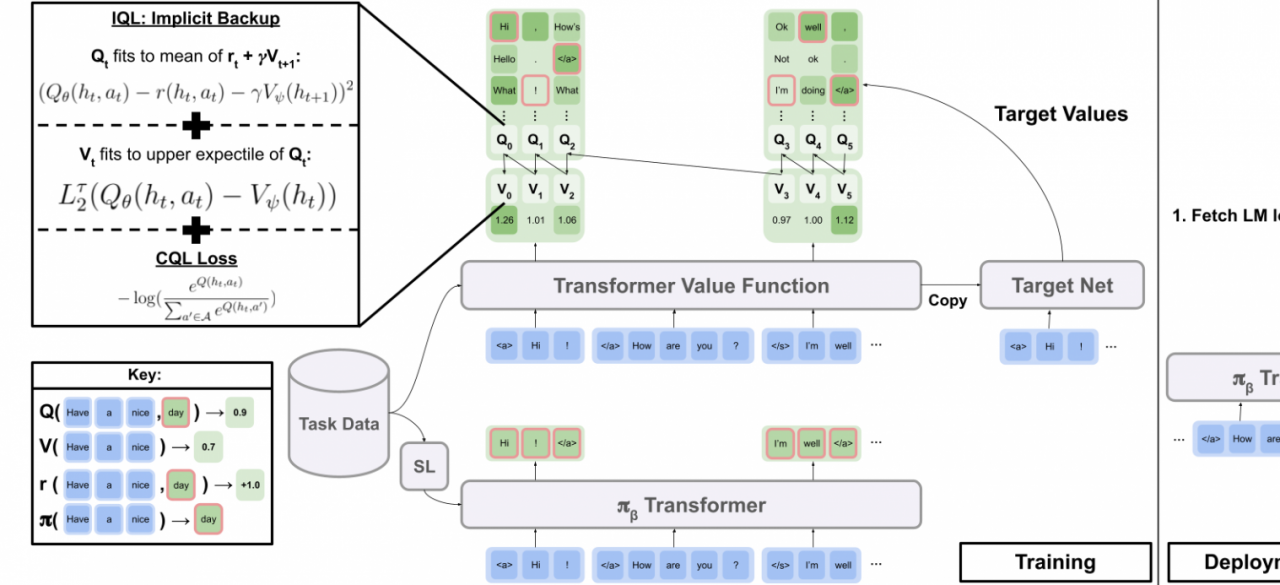
Advances in language models have made it possible to generate highly plausible human-like text. However, the leap from believable and realistic text generation to controllable and useful dialogue agents requires addressing a number of additional challenges: (1) Such dialogue agents must be controllable, in the sense that it must be possible to define specific objects for these dialogue agents to optimize. (2) They must be factual in their responses with respect to a database or manual that defines the desired behavior, while still retaining the common sense and natural flow inherited from language model training. (3) They must be interactive and responsive to humans, aware of the fact that they are participating in a dialogue with a person rather than simply generating a string of text. (4) It must be possible to specialize them to particular downstream tasks with minimal manual data collection, potentially using only prompting and synthetic data generation. The objective of this project is to leverage tools in reinforcement learning to address these challenges, developing dialogue agents trained with a combination of language modeling and value-based reinforcement learning to optimize long-horizon objectives in human-interactive settings. The insights that we will leverage to make this possible will include: (a) Application of multi-step RL to train dialogue agents to maximize reward functions that depend on user responses – i.e., instead of simply optimizing the model to say things that human supervisors think are good, we can train the model to elicit a response that is desired (e.g., a customer service bot that causes customers to say that they are satisfied with the service). (b) Evaluating responses via learned reward models that score the degree to which each conversation is factual, elicits the desired user responses, and displays other desired qualities; our key insight is that such evaluation functions can also be produced via pre-trained language models. (c) Developing techniques that can enable such systems to be trained on synthetic data. (d) Endowing these agents with the ability to utilize “tools” (i.e., databases and other computer programs) to produce factual answers.
| principal investigators | researchers | themes |
|---|---|---|
| Sergey Levine | natural language, dialogue, reinforcement learning |